IKAnalyzer
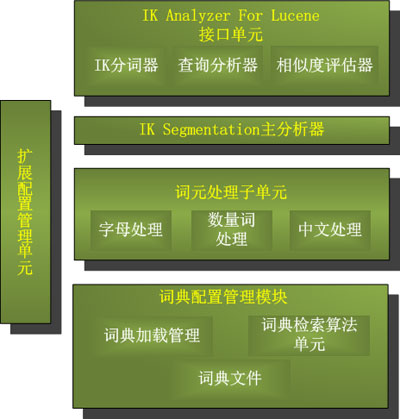
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IKAnalyzer3.0特性:
- 采用了特有的“正向迭代最细粒度切分算法“,具有50万字/秒的高速处理能力。
- 采用了多子处理器分析模式,支持:英文字母(IP地址、Email、URL)、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。
- 优化的词典存储,更小的内存占用。支持用户词典扩展定义
- 针对Lucene全文检索优化的查询分析器IKQueryParser(作者吐血推荐);采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高Lucene检索的命中率。



网友留言/评论
我要留言/评论
相关开源项目
mmseg4j:mmseg4j用Chih-Hao Tsai 的MMSeg算法实现的中文分词器,并实现lucene的analyzer和solr的TokenizerFactory以方便在Lucene和Solr中使用。
起点R3企业级搜索引擎: 起点R3企业级搜索引擎是起点软件提供的企业搜索解决方案,支持企业环境下的数据访问控制(ACL),能够通过定义用户数据访问权限来控制检索数据的安全。
R3是一个强大的,高性能的JAVA企业级搜索引擎产品,R3构建于Solr和Lucene之上,集成了POI、PDFBox和Apache Tika等第三方开源项目,在R3企业级搜索平台上,你可以搜索出你企业所有相关的内容包括网站、邮箱、ECM, CRM。R3使用一中新的集群模式来实现分布式和集群功能,通过扩展计算能力,R3能够支持上千G文档,完成复杂的并行运算;R3能够以集群模式运行来提高系统的可用性。它支持超过15种语言的多语言搜索,能够集成文档自动分类和聚类功能,能够为文档自动、智能的添加标签和关键字。可以通过采集器为索引库定制数据来源,采集器通过插件的方式扩展。默认提供数据库、邮件、本地文件系统、网络文件系统、FTP、Domino、CSV、Access的采集器。R3基于Solr之上,所以在Solr中的层面搜索、同义词等都被完整的保留了下来。R3通过作业调度系统实现了任务的自动化采集、能够增量索引,支持数据更新,能够通过可视化的方式对索引字段进行管理。R3具备用户和用户组管理,R3可以对数据类型定制,支持分词器、过滤器、缓存管理。R3能够很容易的集成Hadoop和HBase。此外它还开发多种编程语言的API包括:Ruby、PHP、Java、Python、JSon、C#、ColdFusion。
R3是一个强大的,高性能的JAVA企业级搜索引擎产品,R3构建于Solr和Lucene之上,集成了POI、PDFBox和Apache Tika等第三方开源项目,在R3企业级搜索平台上,你可以搜索出你企业所有相关的内容包括网站、邮箱、ECM, CRM。R3使用一中新的集群模式来实现分布式和集群功能,通过扩展计算能力,R3能够支持上千G文档,完成复杂的并行运算;R3能够以集群模式运行来提高系统的可用性。它支持超过15种语言的多语言搜索,能够集成文档自动分类和聚类功能,能够为文档自动、智能的添加标签和关键字。可以通过采集器为索引库定制数据来源,采集器通过插件的方式扩展。默认提供数据库、邮件、本地文件系统、网络文件系统、FTP、Domino、CSV、Access的采集器。R3基于Solr之上,所以在Solr中的层面搜索、同义词等都被完整的保留了下来。R3通过作业调度系统实现了任务的自动化采集、能够增量索引,支持数据更新,能够通过可视化的方式对索引字段进行管理。R3具备用户和用户组管理,R3可以对数据类型定制,支持分词器、过滤器、缓存管理。R3能够很容易的集成Hadoop和HBase。此外它还开发多种编程语言的API包括:Ruby、PHP、Java、Python、JSon、C#、ColdFusion。
Nut: 只为lucene提供分布式搜索框架。理论上可对千G以上索引文件支持数千万级的用户搜索访问。Nut由Client、Server、Cache和DB四部分构成。Client处理用户请求和对搜索结果排序。Server对请求进行搜索,Server上只放索引,数据存储在DB中,Nut将索引和存储分离。Cache缓存的是搜索条件和结果文档id。DB存储着数据,Client根据搜索排序结果,取出当前页中的文档id从DB上读取数据。
YaCy:YaCy基于p2p的分布式Web搜索引擎.同时也是一个Http缓存代理服务器.这个项目是构建基于p2p Web索引网络的一个新方法.它可以搜索你自己的或全局的索引,也可以Crawl自己的网页或启动分布式Crawling等.
Paoding:Paoding中文分词是一个使用Java开发的,可结合到Lucene应用中的,为互联网、企业内部网使用的中文搜索引擎分词组件。Paoding填补了国内中文分词方面开源组件的空白,致力于此并希翼成为互联网网站首选的中文分词开源组件。Paoding中文分词追求分词的高效率和用户良好体验。
Bobo: bobo-browse是一用java写的lucene扩展组件,通过它可以很方便在lucene上实现分组统计功能。
比如说搜索电脑,可以得到cpu是intel的有几条命中记录,cpu是amd的有几条命中记录。收录时间:2010-11-18 11:41:18
比如说搜索电脑,可以得到cpu是intel的有几条命中记录,cpu是amd的有几条命中记录。收录时间:2010-11-18 11:41:18
Solandra: Solandra是一个实时分布式搜索引擎,基于Apache Solr和Apache Cassandra构建。其核心,Solandra是Solr与Cassandra的一个紧密集成。这意味着Solr与Cassandra将在单个JVM中同时运行,文档(Documents)采用Cassandra的数据模型进行存储和分发。 1、提供开箱即用的Solr功能包括:搜索、faceting、高亮等。 2、通过Cassandra管理复制,分片,缓存和压缩。 3、Multi-master (可以读写到任何节点)。 4、能够很方便添加新的SolrCores并且不需要重新启动整个集群。
BDDBot:BDDBot是一个简单的易于理解和使用的搜索引擎。它目前在一个文本文件(urls.txt)列出的URL中爬行,将结果保存在一个数据库中。它也支持一个简单的Web服务器,这个服务器接受来自浏览器的查询并返回响应结果。它可以方便地集成到你的Web站点中。
Nutch:Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。
Lucene:Apache Lucene是一个基于Java全文搜索引擎,利用它可以轻易地为Java软件加入全文搜寻功能。Lucene的最主要工作是替文件的每一个字作索引,索引让搜寻的效率比传统的逐字比较大大提高,Lucen提供一组解读,过滤,分析文件,编排和使用索引的API,它的强大之处除了高效和简单外,是最重要的是使使用者可以随时应自已需要自订其功能。