












成功解决:速度提高75倍以上
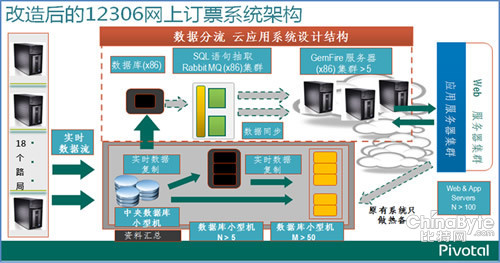
2012年3月开始,铁路总公司(原铁道部)开始调研、改造12306。2012年6月选择了Pivotal GemFire分布式内存计算平台(Distributed In-memory computing)改造12306,由铁科院项目小组负责人王明哲主任和资拓宏宇(IISI)信息科技有限公司在铁科院主管朱建生所长领导下提供技术实施。一期先改造12306的主要瓶颈——余票查询系统。9月份完成代码改造,系统上线。2012年国庆,又是网上订票高峰期间,大家可以显著发现,可以登录12306,虽然还是很难订票,但是查询余票很快。2012年10月份,二期用GemFire改造订单查询系统(客户查询自己的订单记录)。2013年春节,又是网上订票高峰期间,大家可以显著发现,可以登录12306,虽然还是很难订票,但是查询余票很快,而且查询自己的订票和下订单也很快。
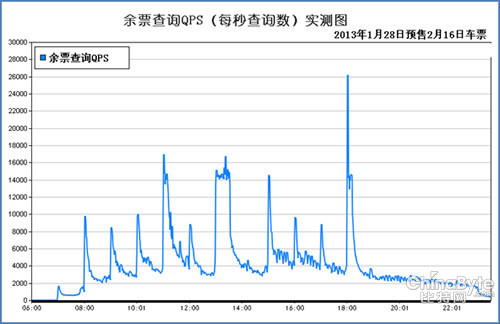
根据系统运行数据记录,技术改造之后,在只采用10几台X86服务器实现了以前数十台小型机的余票计算和查询能力,单次查询的最长时间从之前的15秒左右下降到0.2秒以下,缩短了75倍以上。2012年春运的极端高流量并发情况下,系统几近瘫痪。而在改造之后,支持每秒上万次的并发查询,高峰期间达到2.6万个查询/秒吞吐量,整个系统效率显著提高。如上图所示。
订单查询系统改造,在改造之前的系统运行模式下,每秒只能支持300-400个查询/秒的吞吐量,高流量的并发查询只能通过分库来实现。改造之后,可以实现高达上万个查询/秒的吞吐量,而且查询速度可以保障在20毫秒左右。
新的技术架构可以按需弹性动态扩展,并发量增加时,还可以通过动态增加X86服务器来应对,保持毫秒级的响应时间。
技术革命一步跨越三代
12306能够取得这样翻天覆地的效果,靠技术上的小修小补是不可能的,必须有全新的思路,能够给性能提升带来杠杆式的作用。12306发现GemFire分布式内存数据平台就是这样一种技术。
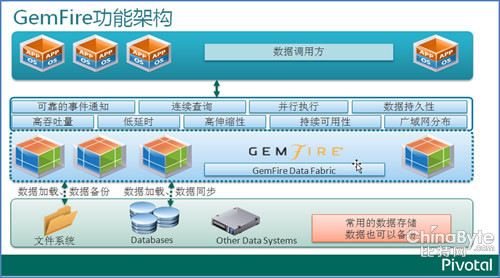
GemFire分布式内存数据平台的技术原理如上图所示:通过云计算平台虚拟化技术,将若干X86服务器的内存集中起来,组成最高可达数十TB的内存资源池,将全部数据加载到内存中,进行内存计算。计算过程本身不需要读写磁盘,只是定期将数据同步或异步方式写到磁盘。GemFire在分布式集群中保存了多份数据,任何一台机器故障,其它机器上还有备份数据,因此通常不用担心数据丢失,而且有磁盘数据作为备份。GemFire支持把内存数据持久化到各种传统的关系数据库、Hadoop库和其它文件系统中。
大家知道,当前计算架构的瓶颈在存储,处理器的速度按照摩尔定律翻番增长,而磁盘存储的速度增长很缓慢,由此造成巨大高达10万倍的差距(如上图)。这样就很好理解GemFire为什么能够大幅提高系统性能了。
按照计算与存储的关系,我们可以将计算架构分为四代:
第一代,基于磁盘的单一系统:计算过程中需要从磁盘读取数据。小型机、大型机是其中的佼佼者,将单一系统的性能做到极致。
第二代,基于磁盘的分布式集群系统:计算过程中需要从磁盘读取数据,但通过分布系统将数据分散到不同的服务器磁盘上,提高整个系统的处理能力。目前很多大型互联网和电子商务公司采用基于X86服务器的分布式集群系统,依靠海量的X86服务器部署解决高流量并发的问题。
第三代,基于内存的单一系统:将整个数据库放在内存中,计算过程不需要从磁盘读取数据。整个系统的性能取决于单一系统的性能。传统的内存数据库就是这样的系统,对于企业级的应用可以很好地解决访问速度的问题,但面对海量数据或是海量并发访问的扩展性问题就无能为力。
第四代,基于内存的分布式集群系统:GemFire就是这样的系统,并行计算是其关键技术之一,因而可以通过增加服务器部署规模,在内存计算的基础上,线性扩展性能。
12306之前采用Unix小型机架构,采用GemFire技术改造成Linux/X86服务器集群架构,就意味着一下跨越三代。从小型机到大内存X86服务器集群,不仅让性能提升了一个数量级,而且成本也要低得多。
GemFire是Pivotal企业级大数据PaaS平台的一部分。Pivotal公司的企业级大数据PaaS平台主要有三个层次:云基础架构层Cloud Fabric、大数据基础架构层Data Fabric、应用开发基础架构层Application Fabric。GemFire属于大数据基础架构层,此外,Greenplum数据库也属于这一层;云基础架构层的技术是Cloud Foundry;应用开发基础架构层的技术是Spring Framework和RabbitMQ等。